Quick Start Guide
API Reference
Check out the API Reference to see all of the available endpoints and options for integrating Trieve into your application.
Getting Started
Get started with Trieve quickly.
Build Search for a Job Board
Learn how to build a search experience for a job board using Trieve.
Build Search for Ecommerce
Learn how to build a search experience for an ecommerce platform using Trieve.
Demos of Trieve in Action
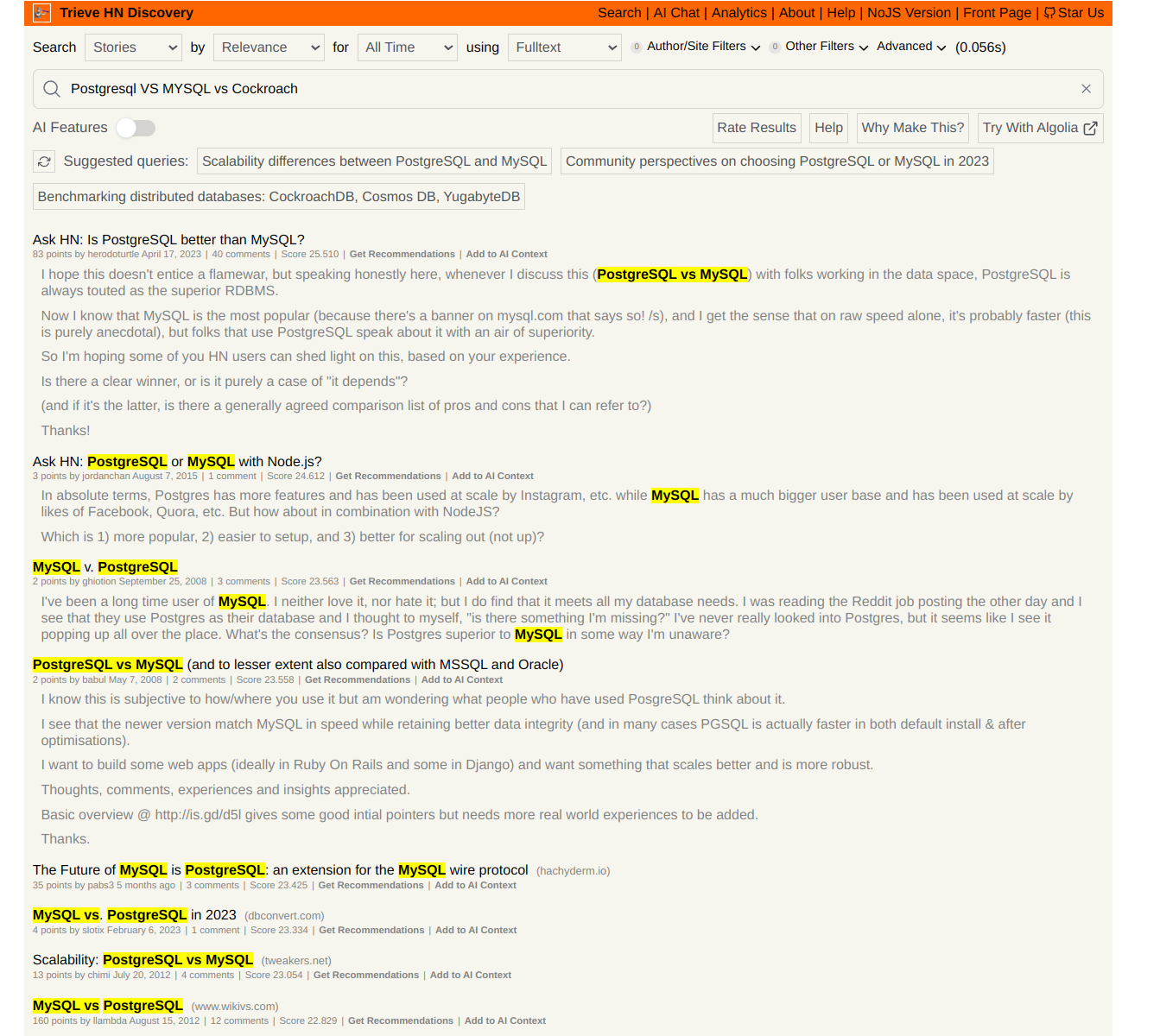
Hackernews
YCombinator Companies
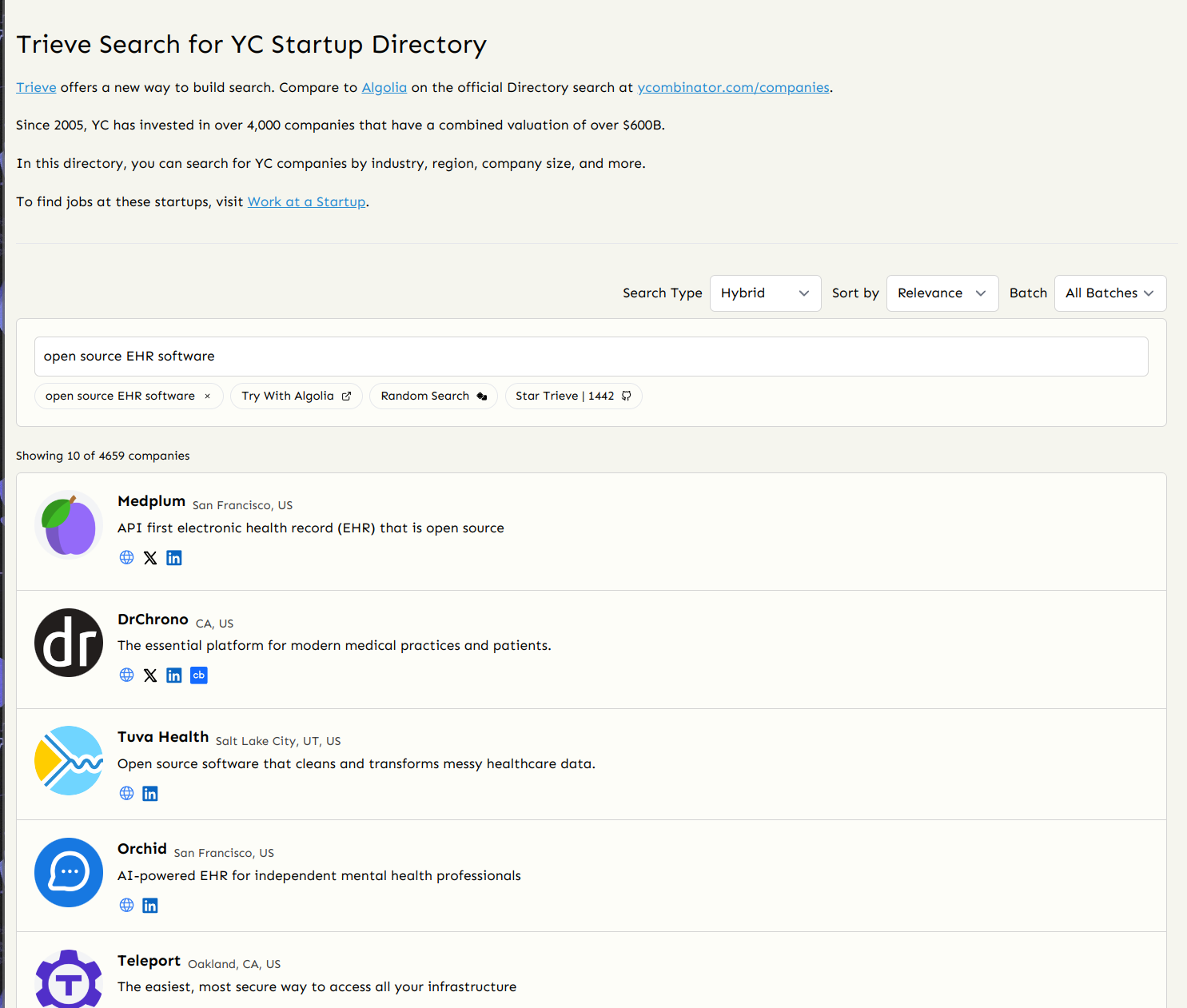
- YCombinator Companies Search - 📝 Building Search For the YC Company Directory With Trieve, Bun, and SolidJS
- SteamDB Search
- This documentation site itself! (and all Mintlify documentation sites)
Client Libraries
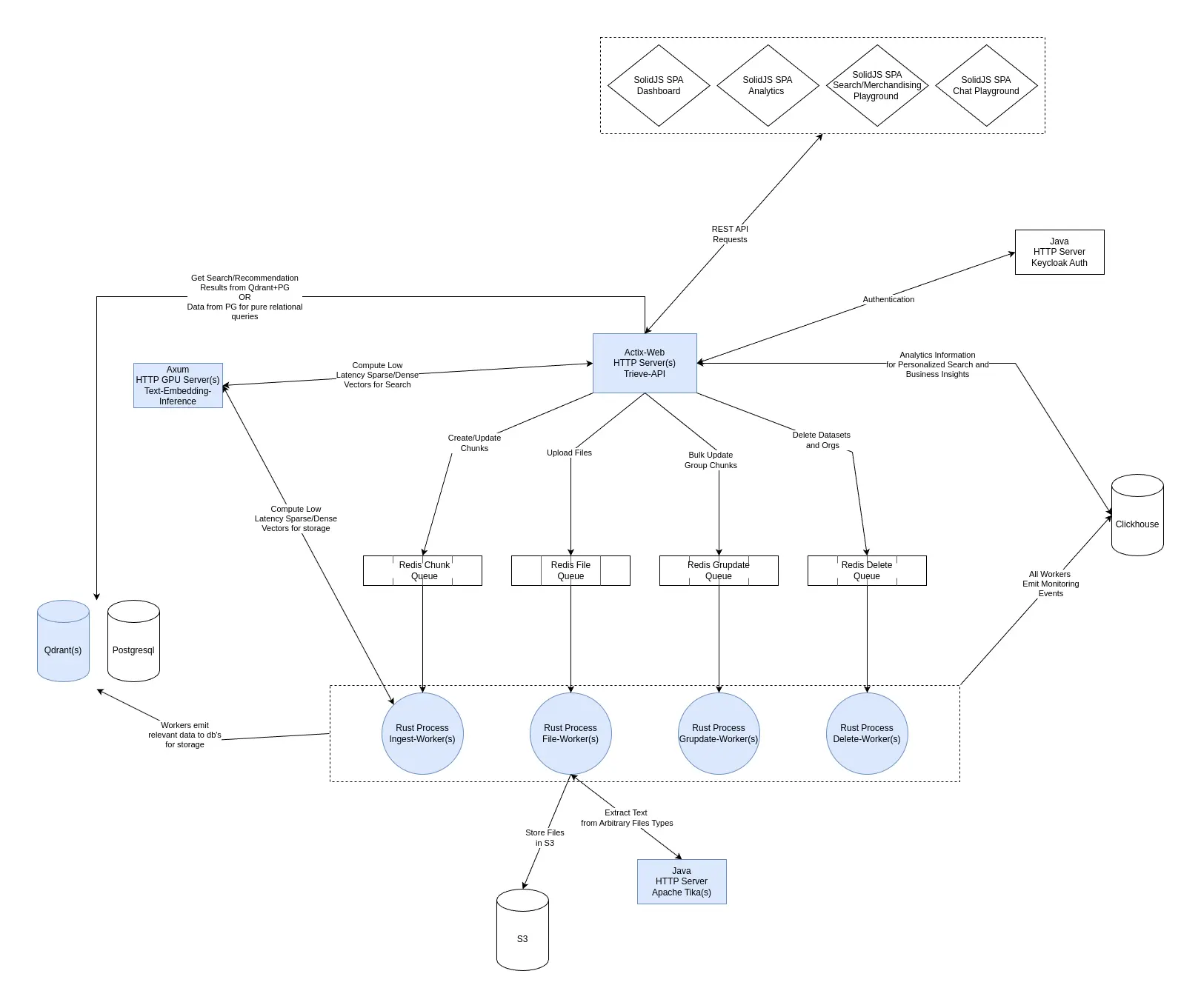
System Diagram
Services in blue are horizontally scalable and can be run in a distributed manner.