Steps to Set Up the Demo
-
Clone the repository:
-
Install the required dependencies:
Install the dependencies by running:This demo uses Bun as a runtime. Install Bun by running:
- Create an account on Trieve: Go to Trieve Dashboard and create an account.
- Create a new dataset and copy the dataset ID. You can either create a dataset on the Trieve Dashboard or use our CLI
- Create a new API key and copy the API key.
-
Create an
.envfile in the root of the project and add the following environment variables: -
Download the dataset
-
Run the demo:
-
View the results
Head over to https://search.trieve.ai and select your dataset.
Try out a few sample queries like
software engineer at google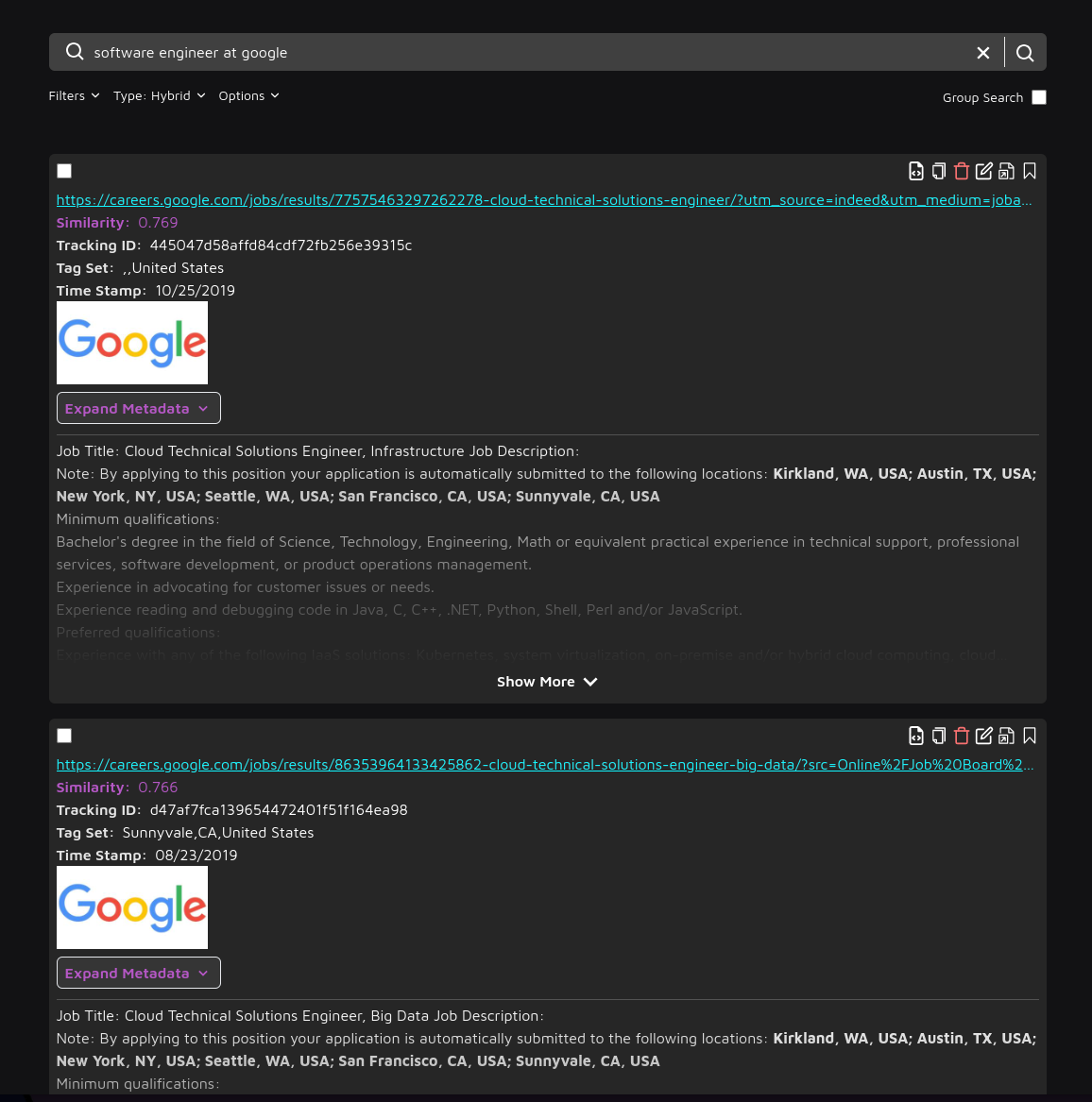 or
or
show me some listings knowing I have experience as a mechanic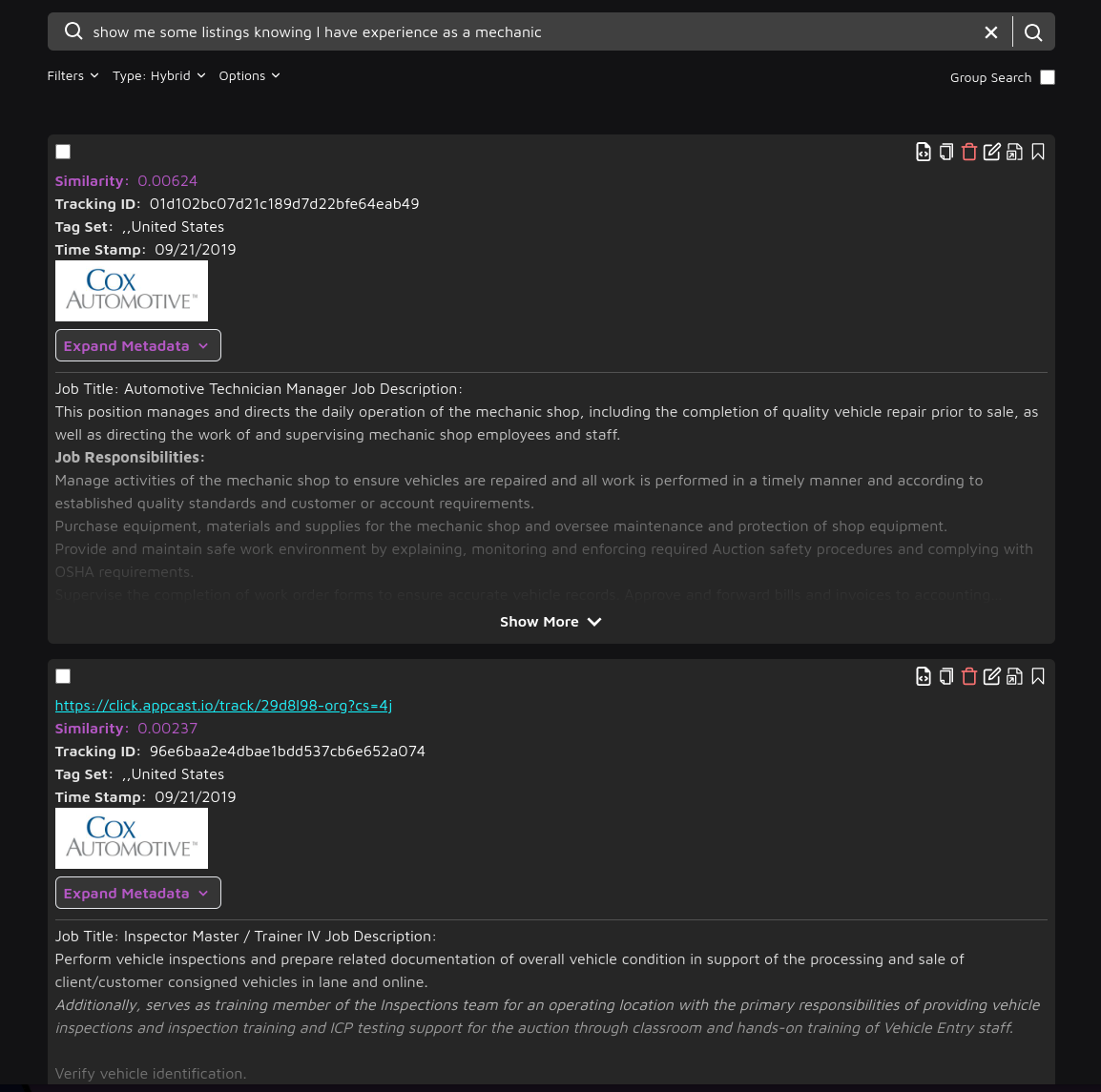
Breakdown of the script
Creating a data model to represent the data
When we receive the CSV data, we need to turn it into a data model to be able to effectively pull the data out of it. The data model for this CSV looks like:Creating the Searchable Chunk HTML
The Chunk HTML should contain the data that we want to be searchable. In this case, we include the job title, description and other text fields that provide more context to the embedding model so that it can generate a better embedding to represent the job.